
PDF達人(PDF文書テキスト自動抽出システム)こんなことにお困りではありませんか?
PDFファイルで「注文」や「情報」が送られてくる。この文書を印刷し、都度、別システムに手で入力する。
→ 打ち誤り、誤転記が心配。 → 枚数が多く、字が小さく、手入力に作業負荷がかかっている。 → PDFを印刷するための紙やトナー(インク)を節減したい。 → PDF文書の配列は、複数の パターンがある。 「PDF達人」が問題を解決します。
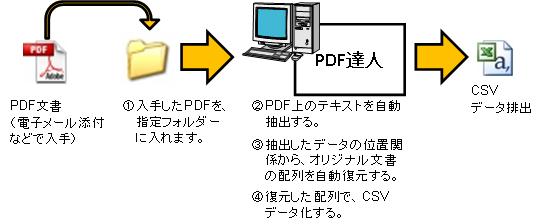
このような場合、弊社「PDF達人」が、PDFファイルの文字情報を自動抽出し、CSVファイル化し、別システムへ連携させます。自動的にPDFのテキストを抽出し、オリジナル文書の配列を自動復元します。これは他のソフトでは類を見ません。弊社は「アナログ」を「デジタル」へ変換することを課題としています。
 期待される効果
1)正確確実化
PDFファイルのテキストを抽出することにより、正確確実なデータが得られます。 2)自動化 プログラムにより、指定フォルダーに入れ込むだけで、自動的に処理され結果が得られます。 3)効率化 OCRと比較した場合、確認のために必ず人による目検が必要で、オペレーターに負荷と時間(コスト)がかかります。テキスト抽出は、指定フォルダーへ投入する以外、全自動で人手はかかりません。 4)汎用化 MS WORDやExcelなどの原本電子ファイルから、直接PDF化したファイルであれば、同様のテキスト抽出が可能です。 価格
※打合せ、仕様書作成、貴社システムとの連携部、導入現調、取扱説明などは別途となります。 動作環境
備考

|
FAX-OCRソリューションなどで、「アナログ」と「デジタル」を「システム」で連携させます!