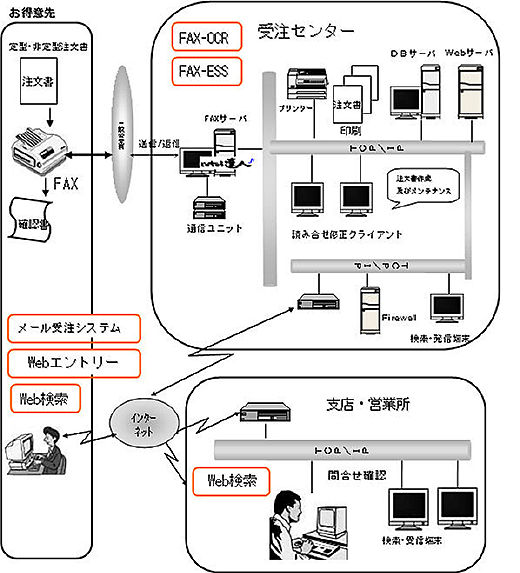
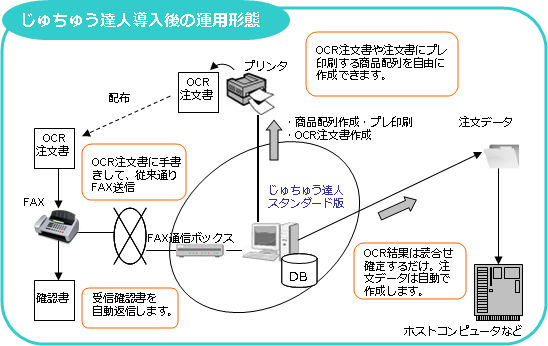
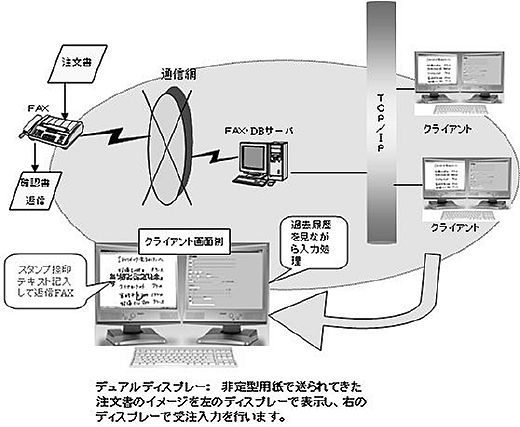
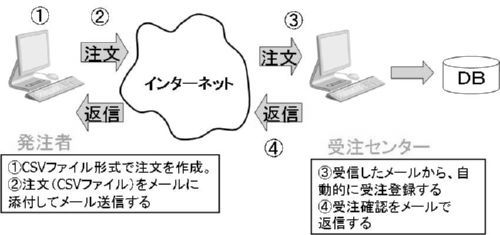
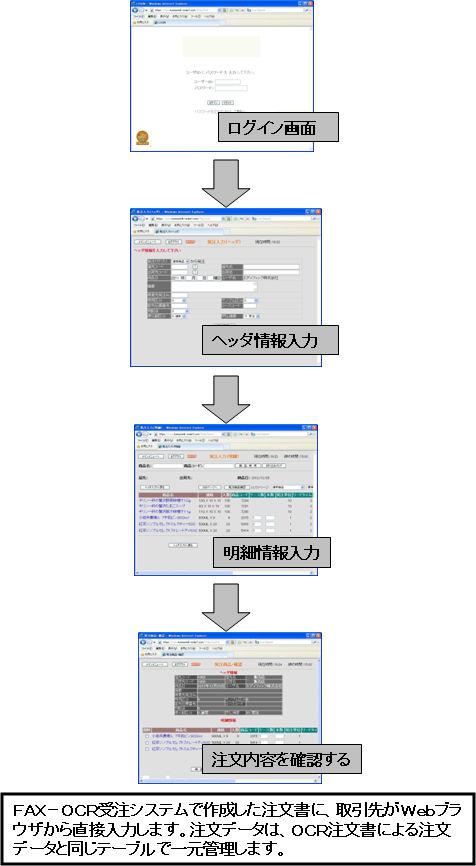
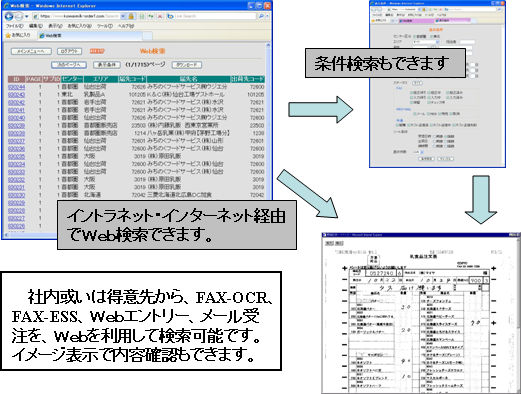
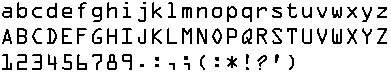|
|
■FAXの原理
|
|
|
|
ファックス機器(通称FAX)とは、正式名称を「ファクシミリ(Facsimile)」と呼び、主に、
・光学的画情報読取装置(スキャナ)
・電話回線伝送装置(モデム)
・電気的画情報印刷装置(プリンタ)
の3つの機能装置の組合せによって構成されています。A4・B4などの規格化された大きさの用紙の内容を、短時間で遠隔地の相手に送信するために開発されたものです。
スキャナ装置で読み込まれた画情報を電気的なデータに変換し、これをモデムによって、電話回線経由で相手の装置へ伝送します。受信側では、受け取ったデータをプリンタに印刷する事で、あたかも「遠地に居る相手の持っている用紙が、瞬時に手元に届いた」かのような利便性を提供します。
|
|
|
■FAXの歴史
|
|
|
|
FAXの原理の発明は、以外にもその時期は古く、日本の終戦年(1945年)よりも遡ること約100年も前の1843年に、ヨーロッパの発明家によって特許が取得されていました。但し、その仕組みとは、目の前の装置で画像の取込と再生をするものに過ぎず、遠隔地への伝送が実用レベルにまで実現するまでに、ここから実に、80年あまりの歳月を要しました。
この約80年の間にも、軍用として、FAXの仕組みは改良が続けられたものの、速度・品質・価格などの観点から、民生レベルへの普及にはとてもほど遠い状態が続きました。しかし、1928年、日本人の丹羽保次郎と小林正次の手によって改良が施され、性能が一気に上がり、FAX実用化のきっかけとなりました。
FAX実用化の第一号が、1928年11月10日の昭和天皇の即位の礼の儀式(京都府)の写真を、東京の新聞社への伝送に成功した事は有名なお話です。
ただ、現在のような家電製品・事務機器の形態で、一般に普及するまでには、ここからまだ長い、開発発展の歴史を歩む事になります。そして、現在のFAX製品の規格化の第一号として、1968年(昭和43年)に、「G1(Group1)」という規格が勧告。この時こそ、A4サイズの用紙を1枚伝送するのに6分かかるものでしたが、ここから約8年後の1974年(昭和51年)に「G2(Group2)」規格が勧告。A4サイズの用紙1枚の伝送時間が3分と短くなりました。
そして、データ圧縮技術とデータ伝送技術が進んだ1980年(昭和55年)に、現在の普及FAX製品の規格として主力採用されている、「G3(Group3)」規格が勧告。翌年の1981年(昭和56年)には、日本電信電話公社(現在のNTTの前身)により、Fネット(FAX通信網)のサービスが開始。また同時に、G2規格のFAX製品の第一号として、「ミニファックス・MF-1」が発売され、瞬く間にヒットし、FAX普及時代の幕開けを迎えました。
|
|
|
■FAXの仕組み
|
|
|
|
原理の項でも書きましたが、FAX装置は、スキャナ・モデム・プリンタの3つの機能装置の集合体です。このため、FAXの仕組みの説明としては、
・スキャナ装置の原理
・モデム装置の原理
・プリンタ装置の原理
を基礎技術として、これらの機能装置間のデータ移送や遠隔地へのデータ伝送をどうやって行っているのか、またその速度性能向上という、応用技術の説明となります。
[1] 基礎技術:それぞれの装置の原理
|
|
|
|
|
(1) スキャナ装置の原理
|
|
|
|
|
|
読み取る原稿に対して光を当て、その反射光を光学センサーで読み取り、
・反射したところ=白い(光を反射)
・反射しなかったところ=黒い(光を吸収)
と判断し、原稿というアナログな情報を、「白黒の2値情報」というデジタルな情報に置き換える装置です。
文書や写真のように、細かい白黒情報を高精度で読み取るために、原稿1枚に対して、目の細かい方眼紙をかぶせるようなイメージで細分化し、その方眼の目の1マス単位で、前述したように「光を反射=白い/光を吸収=黒い」と判断し、白黒の小さな粒の組合せで、原稿全体の情報を表現する形式に変換します。これを「画像情報のデジタル化」と言い、スキャナ装置の役割となります。
この装置により、光を反射した白い部分を、2進数の0で現し、逆に、光を吸収した黒い部分を、2進数の1で現します。これが、スキャナ装置によってデジタル化されたデータとなります。
|
|
|
|
|
(2) モデム装置の原理
|
|
|
|
|
|
色々なデジタル情報データを、送信側として遠隔地に伝送するため、2値化された情報(0/1)を、いったん「音」に変換して、電話回線に流す役割を持つ装置です。
※FAXが通信を始める際に、「ピー」「ガー」という音を発しているのを聞いた事があると思いますが、あの音が正に、アナログ変換されたデジタル情報そのものです。
また逆に、受信側としては「音」として流されてきたものを聞き取り、これを2値化された情報(0/1)に戻す役割を併せ持ちます。
この「デジタル情報データを、音というアナログな情報に変換する」事を、「変調する」と言い、英語ではモジュレータ(modulator)と言います。
また、「音というアナログ情報に変換されたものを聞き取り、再び元のデジタルな2値化情報(0/1)の形に再変換する」事を、「復調する」と言い、英語ではデモジュレータ(demodulator)と言います。
実は、モデムという単語は、この「モジュレータ」と、「デモジュレータ」の単語のそれぞれの頭文字を組み合わせて産まれた造語が語源となっています。
【コラム】
また、近年では、この「変調」「復調」の役割の他に、「相手に自動的に電話を掛ける」「相手からの電話を自動的に受ける」という機能(=回線交換機能と言います)も含めて「モデム装置」と言うようになりましたが、初期のモデム装置は、この回線交換機能がありませんでした。このため、モデム装置を使った、初期のパソコン通信のネットワーク(インターネットが普及する以前)では、まず利用者がVANセンターに電話を掛け、その受話器を「モデムカプラ」と呼ばれる装置に装着する事で、変調された音を電話回線に送出するという利用形態からスタートしました。つまり、「回線交換機能」の役目は、始めは人間が直接やっていた、という事です。
後に、モデム装置自身に回線交換機能が標準装備される様になってくると、次第に、モデムカプラによるパソコン通信は影を潜め、発展的に解消されて行きました。
|
|
|
|
|
(3) プリンタ装置の原理
|
|
|
|
|
|
デジタル化されている2値情報(0/1)を、「0=白い部分」「1=黒い部分」と解釈し、これを白紙に対して転写する事で、デジタルなデータを、「紙」という目に見える、アナログな情報に再変換します。
原理的には、スキャナ装置の逆の仕組みとなります。
|
|
|
|
[2] 応用技術:それぞれの装置間のデータの移送とその制御
|
|
|
|
|
(1) 装置間のデータの移送は、デジタル情報の形で行う
|
|
|
|
|
|
基礎技術の項にて、各機能装置は、以下の様な処理を行っている事を説明しました。
・スキャナ装置
|
|
|
|
|
|
|
「紙」というアナログな情報を、「0/1」で2値 表現されるデジタルな情報に変換する。
|
|
|
|
|
|
・モデム装置
|
|
|
|
|
|
|
「0/1」で2値表現されるデジタルな情報を、「音」というアナログな情報に変換(変調)し、電話回線にて相手へ伝送(送信側)する。
また、受信側のモデム装置では、電話回線にて相手から伝送されてきた「音」というアナログな情報を聞き取り、デジタルな情報に再変換(復調)する。
|
|
|
|
|
|
・プリンタ装置
|
|
|
|
|
|
|
再変換されたデジタルな情報を、「0=白い部分」「1=黒い部分」と解釈し、これを白紙上に転写する事で、再び「紙の上」のアナログな情報に変換する。
この説明からも判るように、各装置間のデータ情報の移送は、全て「デジタル情報」の形で実現されています。
|
|
|
|
|
(2) 各機能装置の制御、処理速度について
|
|
|
|
|
|
各機能装置の間のデータ移送がデジタル情報化されているため、コンピュータによるソフトウェア制御がしやすい事から、FAX機器は急速なメーカー開発参入のターゲットとなって行きました。
また、FAX機器の処理速度という意味で、一番影響があるのが「モデム装置」の部分となります。このモデム装置の処理速度が、FAXの通信速度を決定する最大の要素だったため、「用紙を読み込み、デジタル化するスキャナ装置」や、これをまた「用紙に印刷するプリンタ装置」については、それほど劇的な速度性能改善を必要としなかった事も、FAX製品市場へのメーカー開発参入の敷居を低くする要因となりました。
更に、高性能なスキャン速度や、プリントアウト速度を求められないで済むぶん、生産コストを抑える事が出来るため、現在、もっとも普及している規格「G3(Group3)」のFAXでは、大量生産の恩恵を受け、その販売価格がどんどん下がっていく好循環を生むという結果をもたらしました。
現在では、G3規格の拡張規格である「SuperG3」という規格が主流となっています。
G3規格の最大通信速度が、14,400bps であるのに対して、SuperG3規格の最大通信速度が 33,600bps となっており、A4サイズの用紙1枚の伝送時間は、標準値で6秒※という高速化が実現されています。
|
|
|
|
|
|
|
※規格化された標準的な画像書式があり、それを伝送した場合の秒数です。実際には、発信・着信などの回線交換処理に掛かる時間や、写真原稿のようなものを送ると画素量が増え、伝送時間に影響します。
|
|
|
|
|
(3) 画像の伝送速度向上のためのFAX専用圧縮技術の開発
|
|
|
|
|
|
G3規格(SuperG3含む)では、その伝送速度の向上のため、画像の圧縮技術が取り入れられています。その圧縮の技法としては、規格上は様々なものがありますが、G3規格では、FAXで最も多く扱うと想定される「印刷されたビジネス文書」のような、活字文字の多い資料が、一番圧縮効果が高くなるような仕組みを独自に規格化しました。それが、
MH(Modified huffman/モディファイド・ハフマン)
MR(Modified read/モディファイド・リード)
MMR(Modified MR/モディファイド・MR)
という、3つの圧縮手法です。
・基本圧縮技術「MH」
このうち、基本となるのが冒頭の「MH」で、原稿となる用紙1枚の「任意の上下位置」に対して、横方向に1本の線を置き(つまり1次元)、その線の下にある「用紙の上の白黒の状態の変化」を、線の左端から見ていく方式です。下図1をご参照下さい。
|
|
|
|
|
|
|
図1:1本の線の下にある白黒の変化例
□□□□■■■□□□□□□■■□□□□■□□
|
|
|
|
|
|
この図では、白黒の変化を左端から見ていくと、白4/黒3/白6/黒2/白4/黒1/白2と読み取る事が出来ます。この「白黒の変化とその長さ」の情報の形で持つ事によって、画像の情報の大きさを小さくする、つまり「圧縮」する訳です。
また、この手法による圧縮率の高さを維持するため、MH手法では、下記の2点について配慮された設計となっています。
|
|
|
|
|
|
|
・白黒の変化の回数が少ないほど、圧縮率が高くなる。(つまり、紙面に印字されている黒情報が少なければ少ないほど圧縮率が高くなる)
・印刷されたビジネス文書のように「活字文字」の多い文書の特徴としてみられる「横方向の黒点の連続数が2~5程度の情報の出現率が多い」文書を圧縮した際の圧縮率が高くなる。
|
|
|
|
|
|
・応用圧縮技術「MR/MMR」
詳細な説明は長くなるため、ここでは、概要のみの説明とします。基本的な考え方は、
|
|
|
|
|
|
|
・原稿となる用紙1枚の「任意の上下位置」に対して、横方向に1本の線を置き(ここまではMHと同じ)、その線を基準として、その線のすぐ上、またはすぐ下の画像の情報は、基準の線と較べて大きな変化はない。
|
|
|
|
|
|
という特徴を利用するものです。下図2をご参照下さい。
|
|
|
|
|
|
|
図2:基準線の上下ではそれほど大きな変化はない
□□□■■■□□□□□□■■□□□□□■■□:上線
□□□□■■■□□□□□□■■□□□□■□□:基準
□□□□■■■■□□□□□■■■□□■■□□:下線
|
|
|
|
|
|
中心の基準線と較べても、上線や下線との差は大きくない事が判ると思います。これは、ビジネス文書のような活字文字に多く見られる特徴です。これを、「相関関係が小さい状態」と言います。
この特徴を利用し、MR/MMRでは、以下のような圧縮手法としています。
|
|
|
|
|
|
|
・まず「基準線」を、MH手法にて圧縮。
・基準線と、その次(一般的には下)の線の内容を比較し、違いのあるところだけを抜き取り、その結果で得られた線の情報をMH手法にて圧縮。
|
|
|
|
|
|
単純にMH手法だけの圧縮の場合は、線1本毎に処理を完結させて、次の線へと処理を進めていくため、圧縮対象となる情報が一次元的なものに留まり、圧縮率には限界がありますが、MR手法の場合は、上下の線の差分が小さいという特徴を使って圧縮するため、二次元的な圧縮となり、MHよりもより圧縮率が上がります。
ただ、MR手法による二次元的な圧縮には、ある問題も隠れています。それは「回線に乗るノイズ/雑音」です。
ファクリミリが、この圧縮されたデータを電話回線上に「音」として乗せるため、モデム装置にて受信したデータがノイズにて書き換えられてしまい、データとして不正なものになってしまっている可能性があります。
このままでは、線の上下の差分を見る特徴を活かしたMR手法では、画像の伝送中に、あるタイミングでノイズが入ってしまうと、それ以降に伝送する画像が乱れてしまうという問題が発生する事になります。
この事への対処として、MR手法では、画像伝送中に、定期的に「上限の差分を見る処理を中断し、MH手法による圧縮からやり直す」という方法を採用しています。これなら、途中でノイズによる画像の乱れの影響が発生しても、中断後のMH手法による圧縮のやり直しの位置からは、また問題なく画像が伝送できるようになります。
なお、MMR手法については、ISDNなど、高品質でエラーフリー(エラーが発生しても、プロトコルレベルでそれを訂正する仕組みのこと)な通信を利用している場合は、ノイズによる影響を受けない事を前提に、前述したような「定期的にMH手法による圧縮からのやり直し」は行わず、用紙全体を一気にMR手法にて圧縮を行います。これがMMRです。
・圧縮技術のまとめ
|
|
|
|
|
|
|
モデム装置において、通信速度の高速化やエラーフリー機能が無かった時代は、圧縮技術はMHだけでも充分でしたが、モデム装置の通信速度が上がるにつれ、ノイズによる伝送画像品質の低下がみられるようになると、高圧縮化も兼ねてMRが採用されるようになりました。
そして、ISDN回線の登場により、ノイズの影響を受けやすいアナログ回線から、回線品質の高いISDN回線へと利用率がシフトしていくと、更に圧縮率の高いMMR手法での伝送が一般的になりました。
回線品質の向上と、高圧縮率な手法により、FAXの画像伝送速度は、初期の製品と較べても劇的な速さで相手に用紙の内容を伝送できるようになりました。
「G1規格」の頃は、A4用紙1枚に平均6分と言われていましたが、現在主流の「SuperG3規格」では、同じA4用紙1枚で、実質6秒です。また、ISDN回線によって、回線交換(電話を掛ける、受ける手順のこと)の速度そのものも向上している事から、以前は1枚の伝送に実質20秒~30秒掛かっていた伝送時間も、今では10秒を切る場合もあるくらいです。
|
|
|
|
|
(4) ISDN回線専用のFAX通信圧縮技術「G4」
|
|
|
|
|
|
SuperG3規格により、充分に実用化されたFAXですが、更に上の規格も存在します。それが「G4」と呼ばれる規格で、ISDNなどのデジタル回線の利用を前提とし、A4用紙1枚の伝送速度を3秒としています。
ただ、こちらの規格は、利用回線をISDNなどのデジタル回線に限定している事や、対応するFAX機器が高価で、なかなか一般普及には至りませんでした。
現在でも対応機器は存在し、一部の企業では利用されていますが、FAX市場としてはSuperG3規格対応の製品が一番浸透しており、速度的にも画像伝送品質的にも充分に実用レベルである事から、G4規格のFAX機器の利用は相当に限定的なのが実情です。
A4の用紙1枚を、実質10秒~20秒で送れるのに、これを3秒するために、お互いの機器を、わざわざG4対応の高価な製品に買い換える気にはなりません。
|
|
|
■OCRとは
|
|
|
|
OCRとは、「光学的文字認識」の英語表記である、「Optical Character Reading」の頭文字を並べた造語です。その表記の現す通り、記入、もしくは印字されている文字を、光を当てて白黒の陰影情報を電気的に読み取り、その形状を認識して、コンピュータが識別できる文字コードに変換する事を意味しています。
|
|
|
■OCR登場の背景
|
|
|
|
この世にコンピュータが登場して以来、「文字」という伝達手段は、"人が書くもの" と、"印刷物に印字されているもの"という「2大表現」に加えて、「端末の画面」という仮想の2次元空間の上でも利用されるようになってきました。
近年の人々は、文書を「手書きで作成」するのでも「ワープロで作成して印刷」するのでもなく、コンピュータの端末上で直接作成し、そしてそれを「紙に印刷して利用する」のではなく、電子メールや、ワープロソフトの専用書式ファイルのまま、デジタルデータとしてやりとりする方法を、好んで利用するようになってきました。
つまり、「文書」の作成と保管の土台が、「紙」というアナログな世界から解放された訳です。そして、「文書を紙に印刷しない」という利便性は、単純に、その用紙を印刷するための装置や用紙に関するコストの削減に留まらず、その文書を、必要とする相手に、デジタルデータとして、瞬時に届けられるという魅力が付随する事になりました。
もちろん、その文書を「紙」として必要な場合には、いつでも、そのデジタルデータを「印刷」すれば良いため、近年の文書の取扱いのシーンは、「大量の紙の束」から、「パソコンの中のデータ」という、物理的な負担が発生しない方向へと傾倒してきました。
今や、個人のレベルにおいても、相手がパソコンや携帯電話、スマートフォンなどの端末を持っていて、電子メールなどの情報伝達手段を利用できれば、「紙」というアナログなデバイスを介さずとも、気軽に「文字」によるコミュニケーションを取れる時代となっています。
そして、これだけ利便性の高い情報伝達手段を手に入れた人々が、次に考える事。それこそが、
「既に紙に印刷、もしくは手書きされている文書を、デジタルデータに変換することはできないだろうか?」
という事でした。
この時、通常であれば、「紙に既に印刷されている内容を観ながら、ワープロで新規に文書を作成する」という方法であれば、誰でも、紙の文書をデジタル化する事が出来ます。しかし、文書のデジタル化による利便性を追求して来た人々は、更に、これの上を行く発想に行き着きました。それこそが、
「この文書を、自動的にデジタルデータ化する事が出来ないものだろうか?」
という発想でした。これが、後にOCRという認識技術の開発と発展に繋がって行きます。
|
|
|
■登場初期のOCR
|
|
|
|
OCRの歴史は、以外に古く、1900年代の初頭には、既に、その礎となる技術は発案されていました。その方法とは、「予め学習させておいた文字形状のパターンと、光学的に読み込んだ任意の文字形状のパターンを比較する」というもので、「似たものを見つける」という発想での認識技術でした。この発想は、現在の最新のOCR技術の礎にもなっています。
しかし、その速度や精度という面においては、必ずしも実用化のレベルにまでは達せず、永らく、将来性を見込んだ一部の研究者の間だけで開発が進められていました。
もちろん、日本語や漢字などの文字の認識はまだまだ先の話で、この頃は、あくまでも英字や数字が中心の時代です。
|
|
|
■実用化の始まった、中期のOCR
|
|
|
|
1950年代に入ると、アメリカで初の商用OCR装置が実用化され、その利便性の高さは、事務処理の負担の多くを解消しました。この装置は、出版社の販売報告書の自動化や、その後に登場したクレジットカードの番号の読み取りの自動化など、あらゆる方面での活躍が始まりました。
その後、OCR処理の精度の向上を目的として、英字・数字・一部の記号などを、コンピュータが解読し易い(かつ、人間もある程度判別し易い)形状の文字フォントが開発されました。それが、
「OCR-A」フォント
です。このフォントによって、「紙に印刷したものが手元に戻って来たときに、どのような内容のものだったのか」を、自動的に判別できるようになって来ました。一部の応用例として、航空チケットの管理番号の読み取りにも使われるようになった事例もあります。
図1.OCR_A フォント形状サンプル
|
|
|
■OCR技術の近代化
|
|
|
|
前述しましたが、初期~中期のOCR技術は、あくまでも「予め学習させておいたパターンとの比較」つまり、パターン・マッチングの技法によるものでした。
しかし、英字や数字、一部の記号などで、多くの文書を表現出来る英語圏での利用シーンから、漢字やひらがな・カタカナなどの表現が中心の日本や、韓国、中国などの漢字圏にその技術が伝わってくると、当然ながら、「英数字や記号だけでなく、漢字やひらがなやカタカナもOCRしたい」という要望が出てくるようになって行きました。
また、この頃になると、パソコン用のオペレーティング・システムの開発と躍進により、いわゆる「全角文字」の取扱いも必須になってきました。英語圏の範囲であれば、いわゆる「半角文字」だけで済んだのですが、マルチランゲージ化を突き進むパソコン用のオペレーティング・システムにおいて、全角文字の存在は必須であり、OCR技術の側としても、もはや「全角文字のOCR対応」は避けて通れない課題となりました。
ただ、英数字や一部の記号しか扱えなかったOCR技術では、そのままの方法では、全角文字が誇る、数千字の認識などは到底不可能です。あまりにも類似する文字が多く、1文字1文字を、正確に認識するのは不可能に近い、と考えられていました。
そこで考えられた方法が、
「辞書マッチング」
という手法です。これは、任意内容の文書には適用が難しい手法ですが、ある程度、辞書登録化できる情報、例えば、氏名や住所、会社名や商品名など、予め「どのような文字列の記入が見込まれるか」を想定し、それらの単語を、辞書として登録しておく事で、実際に記入され、OCRされた全角の文字列を、この辞書に照らし合わせて、「一番近い単語」を見つけ、それを正解とするものです。
業務上、OCR処理の対象としたい項目が、氏名や住所、会社名や商品名など、予め想定される情報であった場合にのみ、適用できる技術ですが、この技術は、全角文字の認識精度の問題を補うには一定の効果を得られるため、OCR処理の読み取り結果の補完機能として採用されているシーンもあります。
|
|
|
■今後、更に発展するOCR技術
|
|
|
|
近年のコンピュータの性能向上と共に、OCR処理の性能も、劇的に向上して来ました。コンピュータの演算装置の処理速度の問題から、どうしてもその能力を上げられなかったOCR技術も、年を追う毎に上がり続けるコンピュータ演算装置の性能向上の後押しを受け、認識の精度は飛躍的に向上して来ました。
従来は、印刷された文字、つまり「活字文字」がOCR処理の対象の中心に居ましたが、その技術を応用し、近年では、手書き文字の認識の精度も向上して来ています。殴り書きや乱筆など、文字としての把握が難しい例外は別としても、丁寧に書かれた手書き文字であれば、前述した辞書マッチングの手法も含めて、充分に実用レベルに達してきているのが昨今のOCR技術です。
また、OCRとは少しお話が違いますが、みなさんのお手元のパソコンにも入っている「漢字変換プリプロセッサソフト」。例えば、マイクロソフト社標準の「MS-IME」や、日本では有名な、ジャストシステム社の「ATOK」などにも、標準で「手書き文字パレット機能」が付いています。これらの機能を試してみると判りますが、パレットにマウスなどで文字を書いている先から、リアルタイムに、全角文字の候補が次々に表示されて行きます。つまり、記入している最中に、もう文字認識処理が働いている訳です。これは、パソコンが世の中に出始まった初期の頃には考えられなかった事です。
図2.MS-IME による手書きパッドの例
更には、こういった「画面上に直接記入したものを、その場ですぐに文字認識する」という意味では、更なる技術向上が進んでいます。それが、「オンライン文字認識」。OCR(光学的文字認識)とは違い、前述の「漢字変換プリプロセッサソフトの手書きパレット機能」のように、画面上に直接記入したものをその場で認識する技術ですが、先ほどの手書きパレット機能では、「書かれた文字の形状を認識する」のに対して、オンライン文字認識では、「書かれた文字の線の位置や方向」を認識して、文字を識別する技術です。まだまだ研究段階の文字認識技術ですが、近年、文書閲覧と保管のベースが、「紙の上」から「画面の中」へと急速に変貌を遂げている中において、「紙」を対象としたOCR技術から、「画面の中へ直接記入したものが、その片っ端からどんどんと文字変換され、文字データとして確定されていく」という、もはや紙の存在すら必要が無くなっていく時代へと移り変わっていくでしょう。
ビジネスシーンを中心として、手帳の代わりに、タブレットを利用する人が増えて来ています。手書きのメモは、もはや紙の上ではなく、タブレットの上で書かれ、その場で瞬時に文字データ化され、瞬時に世界中に配信され、世界中の人と共有される。そういう時代は、決して遠くはないかもしれません。
|